Cloud migration is the process of partially or completely
transitioning application, data or any business component to a cloud
computing environment. There can be three types of cloud migration,
first, migrate application and data from on-premises data center to
the cloud. Second, is reverse of the first, migrate application and
data back to the on-premise data center. And third, migrate
application and data from one cloud provider to another cloud
provider.
In this blog I will
talk about the benefits and risks of the first type of cloud
migration, that is the migration of data and application from on-site
to the cloud.
Benefits:
Fast-growing
organizations migrate to the cloud to keep the pace of their growth.
Below are the main
benefits of migration application and data from on-premise to cloud.
Scalability: Scalability is one of the big reason for the success of cloud computing. In the on-premise data center, it is difficult to scale resource on the fly to cater to growing demands.
Cost Efficient: Organizations do not have to spend a huge amount of money on data center maintenance, capacity planning, and hardware. You will have a choice of control level of infrastructure with as-a-service options, like IaaS, PaaS, SaaS, FaaS.
Efficiency and agility: Cloud computing enables organizations to get their product to the market with speed. Cloud-based application and data can be accessed from anywhere with any internet-connected device.
Focus on business: Instead of capacity planning and data center maintenance, an organization can focus on its core business so that its growth can be accelerated.
Risks:
There are risks
involved in cloud migration, it is very important to identify if any
risk is involved in migration. Some risks are as below.
The complexity of the existing system: Assessment of complexity of the current application and finding out all the dependencies of that application is equally important for a successful migration to the cloud. If the application is very complex and working perfectly fine in on-premise, traffic is constant and predicted to be constant or having liner growth, you may think twice before deciding it to migrate to the cloud. You should also check eligibility of application to migrate to the cloud. The application may face latency issue after moving to cloud because microservices will communicate over the network. It is very important to know what it takes to modernize application to work in the cloud.
Security: When you are migrating sensitive data, you may not have full control of your data. Also because of compliance requirements, you may not choose to store sensitive data in the cloud. Check this blog to learn more about security: https://ashu.tech.blog/2019/04/12/cloud-security-vulnerabilities-and-threats/
Vendor lock-in: When a customer uses proprietary product and services provided by a cloud vendor and can not migrate back to the on-premise or cannot switch to another vendor product and applications easily is known as vendor lock-in. To avoid vendor lock-in client should negotiate entry and exit strategy with cloud vendor during a migration strategy.
Cloud
security is the security of an application, data, infrastructure, and
network in cloud computing. Security in public cloud is a shared
responsibility between user and cloud service provider. Many
organization uses Hybrid cloud to have better security so that they
can keep the most sensitive data in private cloud within own data
center boundary. Shared responsibility also gets changed with the
cloud vendor and what is in SLA that you signed.
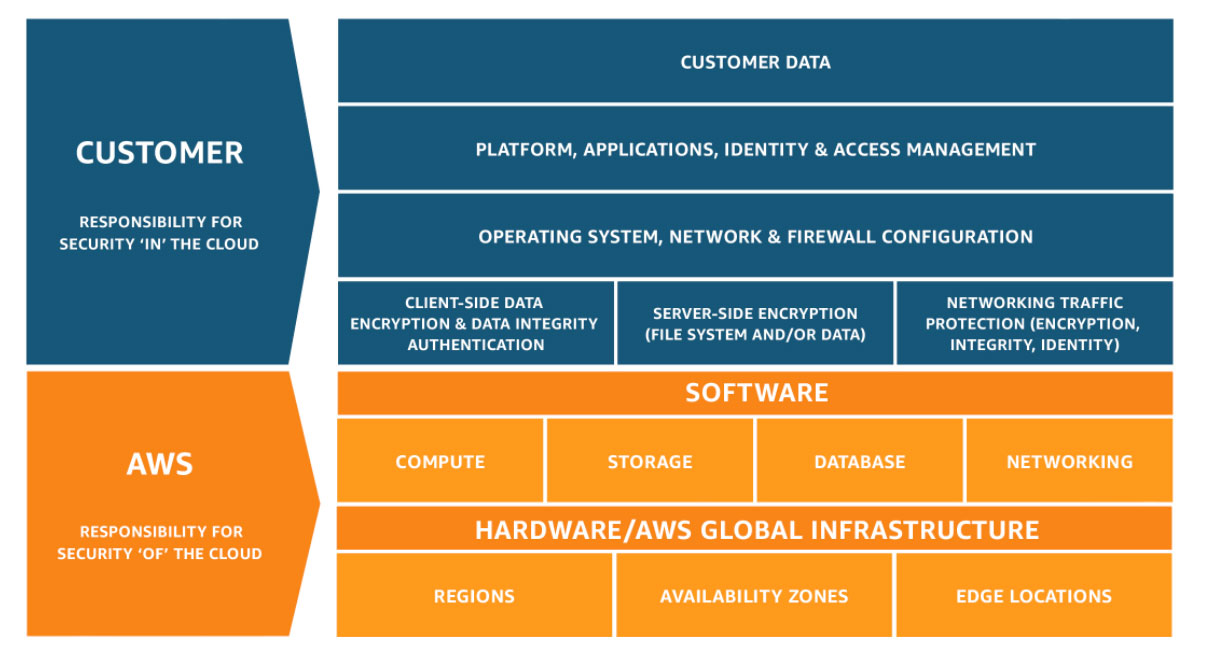
AWS defines shared responsibility as AWS is responsible for “security of the cloud” that means hardware, software, networking, and facilities that run AWS Cloud services. Customer is responsible for “security in the cloud” means If a customer deploys an Amazon EC2 instance, they are responsible for management of the guest operating system (including updates and security patches), any application software or utilities installed by the customer on the instances, and the configuration of the AWS-provided firewall (called a security group) on each instance.
figure: Shared responsibility (AWS)
Before
designing security first you should do the cost-benefit analysis and
risk tolerance of organization. Every workload does not require the
highest level of encryption and security.
If you are migrating from your data center to cloud, you will need
to have all the security measures that you have an on-premises data
center. But when you are migrating from in-house data center to
third-party data center, you have to put some additional security
measure because of multi-tenancy nature of the public cloud.
To ensure security, cloud vendor and cloud customer can use Cloud
Controls Matrix (CCM), a control framework provided by Cloud Security
Alliance (CSA), that provides industry-accepted security standards.
The CSA CCM is specifically designed to provide fundamental security
principles to guide cloud vendors and to assist prospective cloud
customers in assessing the overall security risk of a cloud provider.
As a framework, the CSA CCM provides organizations with the needed
structure, detail, and clarity relating to information security
tailored to the cloud industry.
A report published by Cloud Security Alliance (CSA) about the top threats of cloud computing, using security guidelines and this report below is the main point to consider for security:
Data Breaches: Any data or information that is not intended for unauthorized access is stolen because of human error, application vulnerabilities, or poor security practices. The primary objective of a targeted attack is data breaches.
Weak Identity, Credential, and Access Management: Lack of identity and access management system and credential policy is the main reason for data breaches. Identity management system must support immediate de-provisioning of access to resources when personnel changes. We can consider multifactor authentication system. TLS certificates, keys used to protect the access of data and keys used to encryption of data at rest must be rotated periodically. There should be a provision to enforce change password periodically.
Malicious Insiders: CERN defines an insider threat as follows: “A malicious insider threat to an organization is a current or former employee, contractor, or other business partner who has or had authorized access to an organization’s network, system, or data and intentionally exceeded or misused that access in a manner that negatively affected the confidentiality, integrity, or availability of the organization’s information or information systems.”
Advanced Persistent Threats (APTs) : Spearphishing, direct hacking systems, delivering attack code through USB devices, penetration through partner networks and use of unsecured or third-party networks are common points of entry for APTs. Awareness programs that are regularly reinforced are one of the best defenses against these types of attacks because many of these vulnerabilities require user intervention or action.
Denial of Service (DoS): Denial-of-service (DoS) attacks are attacks meant to prevent users of a service from being able to access their data or their applications. By forcing the targeted cloud service to consume inordinate amounts of finite system resources such as processor power, memory, disk space or network bandwidth, the attacker—or attackers, as is the case in distributed denial-of-service (DDoS) attacks—causes an intolerable system slowdown and leaves all legitimate service users confused and angry as to why the service is not responding.
Network Security in the cloud: Ensuring the confidentiality and integrity of an organization’s data-in-transit is very important in network security. Stratoscale identifies the following four principles of network security in cloud computing:
Isolation between multiple zones should be guaranteed using layers of firewalls.
Network controls for traffic to and from their applications.
End-to-end transport level encryption should be used by applications.
Standard secure encapsulation protocols such as IPSEC, SSH, SSL should be used when deploying a virtual private cloud.
To reduce vulnerability in the cloud, organizations can consider below steps:
Make
sure everyone in the
organization
understands Cloud Service Provider’s shared responsibility model
and its impact based on their role in an
organization.
Good
planning is required for selecting an
appropriate
tool and technology or any applications to move in the
cloud.
Also, a
good amount of analysis and planning needed to
buy vs build analysis.
Ensure
all steps should
be taken to
maintain the
availability
of your application.
Should
have good real-time
and continuous monitoring
and alert mechanism in place, so that you can identify prospective
threat upfront. For example, you started getting a
huge
hit from an
area where you do not have any customer, or you can catch if anyone
trying continuously with a
different
wrong token to access your system.
Always
rotate cryptographic key
and TLS key based on regular or irregular rotation strategy you have
chosen.
Continuously
learning about the latest trends and vulnerabilities and keep
updating your security plan and tools accordingly.
Implements
best practices for deployments and
ensure
to have full automation.
Ensure
proper use of Identity and Access Management (IAM) for assign user
access rights and resource access policies.
New switch expressions will be available as preview feature is JDK 12.
What is a preview feature?
Preview features are available for those who want to use those feature before its final release of JDK. You can use preview feature if you have enabled it for JDK 12, by default it will not be available for you.
Below is how preview
features are defined by OpenJDK:
A
preview language or VM feature is a new feature of the Java SE
Platform that is fully specified, fully implemented, and yet
impermanent. It is available in a JDK feature release to provoke
developer feedback based on real-world use; this may lead to it
becoming permanent in the future Java SE Platform.
It is a fully
implemented feature, released first for developer feedback. It will
be not experimental, high quality and universally available. This
preview feature will be available to enable it to compile and run
time.
To enable it at
compile time by using –enable-preview
as
below:
javac --release 12 --enable-preview Foo.java // Enable all preview features of Java SE 12
and to enable it at run time as below:
java --enable-preview -jar App.jar // Enable all preview features of Java SE 12
The current switch Statement in Java:
Currently, Java is having a switch statement very similar to C or C++ language. It has many case: and break; statements. If you will miss any break statement then your program will not work correctly.
switch (subject) { case PHYSICS: case CHEMISTRY: case BIOLOGY: System.out.println("Science"); break; case GEOGRAPHY: case HISTORY: case POL_SCIENCE: System.out.println("social Sciences"); break; }
The newly proposed switch statements in JDK 12:
The new proposed switch statement for JDK 12 can compute a value or
can execute a statement that will match with a case.
To compute a value now break can have a value that it will return.
Break statement without a value is similar to the old version of
switch statement defined above.
Below is the example mentioned in JDK 12 can have a break statement with value, this is the implementation of switch that can compute a value:
int result = switch (s) {
case "Foo":
break 1;
case "Bar":
break 2;
default:
System.out.println("Neither Foo nor Bar, hmmm...");
break 0;
};
in the above example, the result will be the value break will have at
the time of executing a break statement.
The new switch statement is also proposed to add a new “simplified” form, with new “case L ->” switch labels.
switch (k) {
case 1 -> System.out.println("one");
case 2 -> System.out.println("two");
case 3 -> System.out.println("many");
}
It can have a default case as well:
switch (k) {
case 1 -> System.out.println("one");
case 2 -> System.out.println("two");
case 3 -> System.out.println("many");
default -> System.out.println("default");
}
This is very similar to the earlier switch statement, but a break statement is not needed here. We can use new “case L →” labels to get computed values as well as below:
int numLetters = switch (day) {
case MONDAY, FRIDAY, SUNDAY -> 6;
case TUESDAY -> 7;
case THURSDAY, SATURDAY -> 8;
case WEDNESDAY -> 9;
};
Here numLetters value is dependent on the case executed.
If we need multi-line statement for each case then we can have {} block. If we need multi-line statement but need computed value out of switch statement then we have to use the break statement to return a value similar to earlier example returning value through break statement using new “case L →” labels. Below is the example quoted by JDK 12:
int j = switch (day) {
case MONDAY -> 0;
case TUESDAY -> 1;
default -> {
int k = day.toString().length();
int result = f(k);
break result;
}
};
In either format of case labels, the new “case L →” labels or “case L:” labels, if it is non-void switch, that returns a value, it must be complete with a value or throw an exception. A switch statement cannot be a combination of void and a non-void switch labels. Below switch statements are incorrect:
int i = switch (day) {
case MONDAY -> {
System.out.println("Monday");
// ERROR! Block doesn't contain a break with value
}
default -> 1;
};
i = switch (day) {
case MONDAY, TUESDAY, WEDNESDAY:
break 0;
default:
System.out.println("Second half of the week");
// ERROR! Group doesn't contain a break with value
};
Also as per JDK 12 new switch statement proposal, control statements, break, return and continue, cannot jump through a switch expression, such as in the following:
int k = switch (e) {
case 0:
break 1;
case 1:
break 2;
default:
continue z;
// ERROR! Illegal jump through a switch expression
};
In JDK 12, they may expand switch to support switching on primitive types (and their box types) that have previously been disallowed, such as float, double, and long.
I think these new switch feature will increase the usability of the switch statement.
HTTP/2 is a new version of HTTP, that is a major update of HTTP after
the introduction of HTTP/1.1 in 1999.
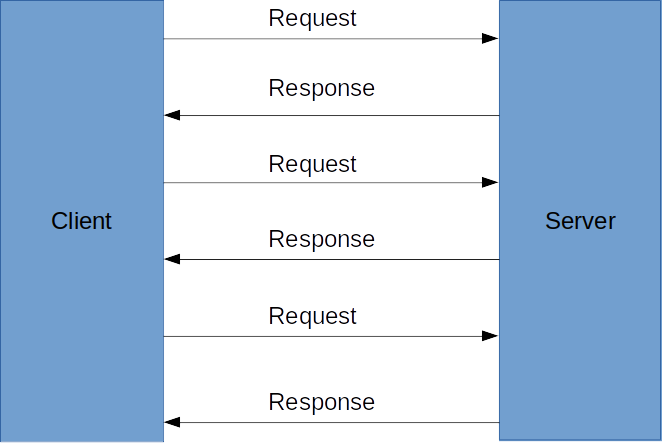
While communicating client with the server, HTTP/1.1 process one
request per TCP connection, to process multiple requests
simultaneously, the client uses multiple TCP connections in parallel.
HTTP/1.1 works on request-response protocol where each connection
supports pipelining. This supports single direction streaming but
does not support bi-directional streaming. HTTP/1.1 supports SSL, but
for that, it establishes an extra connection, that is complete one
extra cycle. More connections result in more wait times.
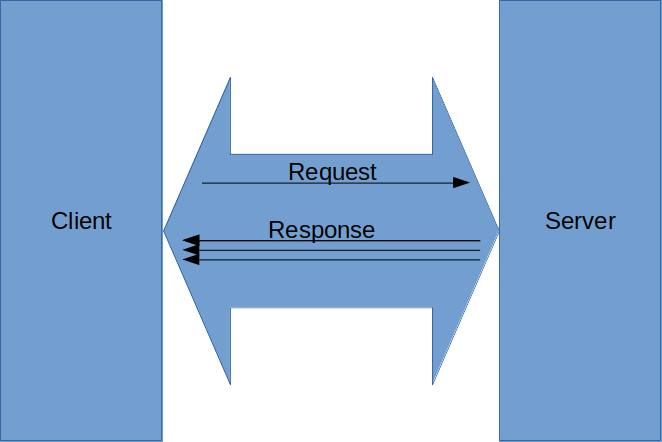
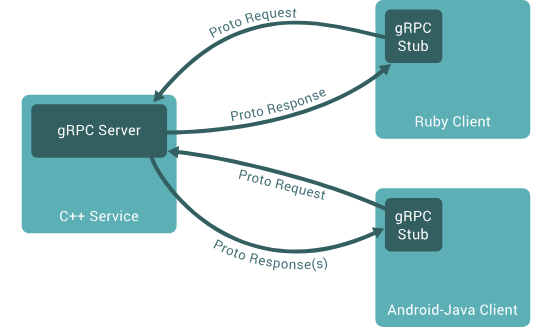
GRPC is a high-performance, open-source universal RPC framework initially developed by Google. It uses Protocol Buffers to define service. It establishes one connection like a tunnel and sends all response in one communication.
Fig: Communication in HTTP/1.1 (REST calls)
In REST, there is a separate request and response for header, body, SSL, etc.. with a separate connection is required. But in gRPC, once a connection is established, the client sends one request and in turns service returns all the response in the same connection.
Fig: Communication in HTTP/2
gRPC is being supported by many languages and platforms. You can generate client and server stubs to communicate between client and server or between services using Protocol Buffers.
Below is officially supported language with supported compilers for
gRPC:
Efficiently
connecting polyglot services in microservices style architecture.
Connecting
mobile devices, browser clients to backend services.
Generating
efficient client libraries.
Core Features that
make it awesome:
Idiomatic
client libraries in 10 languages.
Highly
efficient on the wire and with a simple service definition framework
Bi-directional
streaming with http/2 based transport
Pluggable auth,
tracing, load balancing, and health checking
gRPC introduced three new concepts, that is channels, remote
procedure calls (RPCs) and messages. The relationship between these
three is: each channel can have many RPCs, and each RPC can have many
messages. It has a one-to-many relationship between channels and
RPCs, and again one-to-many relationship between RPC and Messages.
Channels are virtual
connecting between endpoints, RPC is HTTP/2 streams, and messages are
associated with RPC and get sent as HTTP/2 data frames. A data frame
can have many messages, or if one message is too big it can span to
many data frames.
Once connection
established between client and server, it creates like a tunnel and
keeps that tunnel open for communication. For each set of client and
server communication, there is a separate tunnel, in that way it will
make several connections and keep all connections open that make
communication super fast.
Using Resolver and Load Balancer, gRPC keeps the pool of connections healthy, alive and utilized. When a connection fails, the Load Balancer will begin to reconnect using the last known list of addresses, meanwhile, the resolver will begin to re-resolve the list of hostnames. Once resolution finished, the Load Balancer is informed of the new addresses. To check the health of connection gRPC periodically sending HTTP/2 PING frames on connections to determine whether the connection is still alive.
Implementation:
To write gRPC server
or client, first, we can define service in a .proto file and
implement client and servers in any gRPC supported languages.
Unary RPCs: In this method, the client sends a single request to the server and gets back a single response. Example: rpc SayMessage (TestRequest) returns (TestReply) {} This is like a normal function call.
Server streaming RPCs: In this method, the client sends a single request to the server and get a stream to read a sequence of messages until there are no more messages. Here gRPC guarantees message ordering . Example: rpc SequenceOfResponse (TestRequest) returns (stream TestReply) {}
Client streaming RPCs: In this method, the client writes a sequence of messages and send them to the server, once the client finished writing a message it waits for the server to read and send its response. Here gRPC guarantees message ordering. Example: rpc SequenceOfRequest (stream TestRequest) returns (TestReply) {}
Bidirectional streaming RPCs: This is a combination of Server streaming and Client streaming RPCs. In this method both send a sequence of the message using read-write streams. Here also gRPC guarantees message ordering in each stream. Example: rpc SequenceOfRequest (stream TestRequest) returns (stream TestReply) {}
Strategy to migrate from REST to gRPC:
we
have already written lots of microservices using REST, to move those
microservices to gRPC not too much pain if you will plan it
correctly.
You
have all business logic written in each microservices, a plan to
change from REST to gRPC can have below steps:
STEP-1:
Design gRPC API for your similar REST API, for
example.
REST:
POST
test/nameAdd
gRPC
equivalent :
rpc
AddName( Name){ return NameIndex; }
REST:
GET
test/name/{ nameIndex }
gRPC
equivalent :
rpc
GetName( nameIndex ){ return Name; }
STEP-2:
Run both REST and gRPC services initially, so that rest client and
gRPC client both can have access of implemented services.
STEP-3:
Solve problem area, like health check and API discovery.
STEP-4:
Remove REST services.
Current HTTP/2 support:
This is a relatively new technology that big companies already started implementing, still, HTTP/1.1 (REST) is leading in current developments of microservices. Slowly more tools and support will come and confidence will build up for HTTP/2. For sure REST will become thing of past and industry will move to HTTP/2.
An application is a software system that manages data and present information to the end user. The end user could be a human or any other application or service. As per TOGAF technical reference model (TRM), an application can be of two types:
Business Applications: Business applications are the applications that solve a very specific problem related to the particular business domain or industry vertical. For example, the supply-chain application used in the retail industry.
Infrastructure Applications: Infrastructure application are general applications, that solve specific problem across the business domain or across industry vertical. For example, payment service, or email client service, or UX design tool etc. These kinds of applications are considered as a part of IT infrastructure.
Over time business applications become infrastructure applications. For example, Facebook developed to React for their use as a business application, but now React is open source using across the industry has become Infrastructure application.
Most of the time we design and develop business applications and make a build or buy decision (Mostly buy) for Infrastructure applications.
Before start working on application architecture, it is suggested to consider the following steps:
Understand business scenario or architecture vision that contains problem description, detailed objectives, process description, process steps, information flow, and any relevant technical requirement explicitly provided.
Understand the business goal, objective, and constraints.
Check if any architecture artifacts are available to use.
Analyze baseline application architecture, if available (for existing applications).
Analyze target draft application architecture, if provided.
To define target architecture you should refer base architecture of the application. If base architecture is not available or not developed, it can be created first. The base architecture could be a generalized form of the target architecture.
To create target architecture, consider the below steps:
Select Architecture resources for example reference models and patterns.
Select Architecture viewpoints for example applications’ functional or individual users viewpoints, software engineering viewpoint, app-to-app communication viewpoint, and software distribution viewpoint.
As per selected viewpoint, identify tools and techniques, list down all tools and techniques, compare and finalize by doing the formal review with stockholders.
Identify and select best practices.
Factors that impact application architecture is the geographical distribution of applications, communication between applications and components, migration from baseline to target application architecture, gap analysis between baseline and target business and application architecture, use cases of application, and security concerns.
Based on the above information and analysis, you will be able to design core application architecture, and then break up this architecture to project-level architecture. Before start working on application architecture, you should be ready with the architecture vision statement, business goals, business architecture and data architecture documents.
Once the target application architecture is created, The Open Group suggests to examine the following to identify:
Does this Application Architecture create an impact on any pre-existing architectures?
Have recent changes been made that impact the Application Architecture?
Are there any opportunities to leverage work from this Application Architecture in other areas of the organization?
Does this Application Architecture impact other projects (including those planned as well as those currently in progress)?
Will this Application Architecture be impacted by other projects (including those planned as well as those currently in progress)?
Once you have examined your application architecture, modify based on examination if required, and created final architecture then you can proceed to conduct formal stakeholder review. Modify your architecture based on stakeholder review if required, and finalize the application architecture. To finalize application architecture The Open Group suggests the following steps:
Select standards for each of the building blocks, re-using as much as possible from the reference models selected from the Architecture Repository.
Fully document each building block.
Conduct a final cross-check of overall architecture against business requirements; document the rationale for building block decisions in the architecture document.
Document the final requirements traceability report.
Document the final mapping of the architecture within the Architecture Repository; from the selected building blocks, identify those that might be re-used and publish via the Architecture Repository.
Finalize all the work products, such as gap analysis.
Once you have done with finalization steps, create final application architecture documents. User reports, graphics generated by modeling tools to demonstrate key views of the architecture and send these documents to relevant stakeholders, and incorporate feedback.
If you want your cloud provider should take more responsibility and you can focus on your core business (code), in this case, the first thing that comes in mind is PaaS.
PaaS is
great, you just have to manage your code, that is what your core
expertise is. Cloud provider is responsible for almost everything
else.
PaaS, as defined by NIST, is:
“ The
capability provided to the consumer is to deploy onto the cloud
infrastructure consumer-created or acquired applications created
using programming languages, libraries, services, and tools supported
by the provider. The consumer does not manage or control the
underlying cloud infrastructure including network, servers, operating
systems, or storage, but has control over the deployed applications
and possibly configuration settings for the application-hosting
environment.”
Cloud providers come with an approach that how to run the application on PaaS to get maximum benefit, the most discussed approach is the 12-factor approach referred by Cloud Foundry. After going through all the benefits of the PaaS, a strong opinion about PaaS builds up in mind and feel like this is the best solution for deploying the application without any overhead. This is true if you are developing a new application from scratch. This is most suited to the web application or mobile application you are planning to build.
If you already have an application running on your hardware and you are planning to move to the cloud, in that case, is PaaS a good option? You have analyzed effort of refactoring and you are ready to do refactoring of your application to move it to PaaS. But you want to try first and you are not sure which cloud provider you will choose, that could be AWS, Azure, IBM, GCP or any other cloud. In that case, you have to evaluate the cloud platform and decide cloud vendor first before start refactoring.
You have decided to use third-party PaaS like Cloud Foundry or Openshift, so that you may be open for any cloud vendor. By using independent open source PaaS, you will have the flexibility to move your application to any underline IaaS provided by public cloud vendor or own infrastructure that is a private cloud. In this case, you are not locking with any IaaS, but you may still have possibly getting locked with vendors like Cloud Foundry or Openshift.
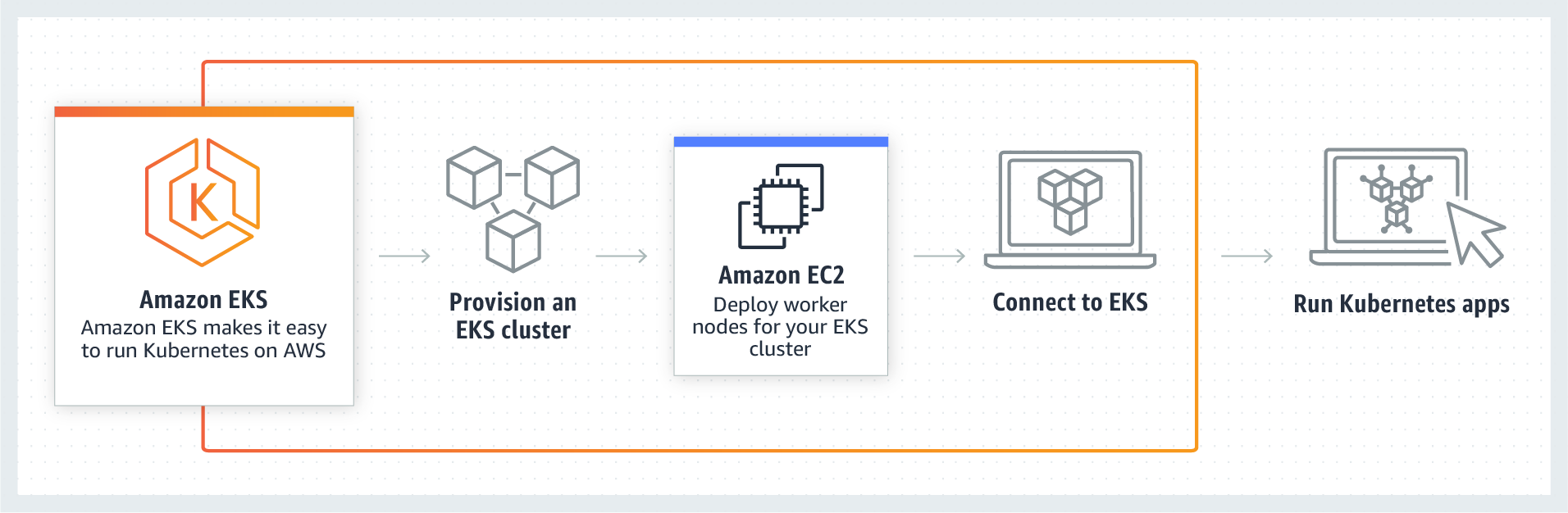
To move existing applications to cloud with minimum infrastructure responsibility, Managed Kubernetes is the best solution. Kubernetes is an open source system for automating deployment, scaling, and management of containerized applications. Managed Kubernetes is a managed service that managed nodes (Instances) of the cluster where containers are running inside pods. Kubernetes can scale without having much burden on the ops team. Kubernetes is a management framework for the container in an IaaS, and Managed Kubernetes is a managed service that allows the user to deploy their code in a container in the provided platform by cloud vendors.
Managed Kubernetes is a “Kubernetes as a Service” that simplifies deployment and you can focus on development. Fully managed Kubernetes is being provided by almost all cloud vendor, as this is an open source solution, you can switch to any vendor any time without any issue.
Figure:
Amazon EKS
Managed
Kubernetes Service advantage:
You can focus on your core business.
You will not run your application in underlying VM using PaaS, instead, you will run your application in containers using Kubernetes service.
Managed Kubernetes service can run on your on-premises, any public cloud, the mix of public and private cloud.
It can run on your laptop, on your data center, and on the public cloud.
Self-healing infrastructure.
No vendor lock-in traps.
Easy audit and log aggregation.
It provides one-click deployment similar to PaaS (or can be deployed with one command).
There
are many hosted solutions available for Managed Kubernetes Engine,
some of them are:
Amazon
Elastic Container Service for Kubernetes (EKS).